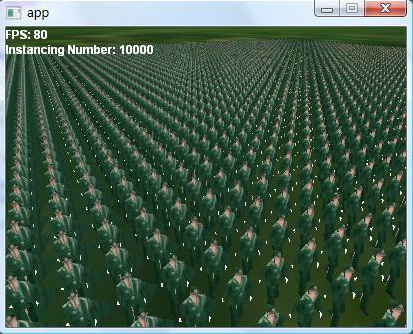
上图是通过Instancing渲染了10000个低精度模型(低于200个面),有skin动画,但是人物没有AI。在实验室Geforce 8800GT的显卡上fps可以跑到80帧。
接着,我给人群加上点简单的AI,每个人物进行向一个目标点移动,于是我在每帧更新的时候添加了如下的这些代码。代码中,MeshInstance是instance的类,对应于一个人物实例,Move是移动人物实例的简单AI函数。对于所有的Instancing数据,我使用一个vector列表存储——m_vpInstancingData。代码通过vector的iterator(迭代器)遍历所有的instance,对每个instance执行Move函数。
for( vector< MeshInstance* >::iterator i = m_vpInstancingData.begin(); i != m_vpInstancingData.end(); i ++ )
{
( *i )->Move();
}
结果,加上这段代码之后,程序的效率居然骤降,如下图,fps只剩下44帧。这让我很是纳闷,因为在加上代码之前,CPU基本上是空闲的,因为所有的骨骼蒙皮+渲染全部都是GPU扛着,而在CPU加上一个10000次的for循环后,整体效率大打折扣。它的杀伤力有这么大么……CPU不太可能这么低能。

然后,我把(*i)->Move()这行代码注释掉了,仍然只有40多帧,即一个只是10000次的空for循环,仍然是效率的瓶颈,10000次的Move根本不是问题。
难道是迭代器在影响效率?于是把代码改成了下面这样,不用迭代器遍历vector,而直接使用数组形式访问vector来遍历。
for( int i = 0; i < NUM_INSTANCE; i ++ )
{
m_vpInstancingData[i]->Move();
}
再次执行之后,fps又回归80帧!!

对于vector的遍历,一直以来一直都是通过迭代器遍历,但对于大型vector它居然会如此的影响效率,也是到今天才刚发现。但是STL的设计本来就是奔着方便高效的啊,迭代器不至于效率影响这么大吧,可能与Debug模式有关。于是,我做了一个小实验,代码如下。
#include <iostream>
#include <vector>
#include <time.h>
using std::vector;
using std::cout;
using std::endl;
#define MAX_NUM 1000000
int _tmain(int argc, _TCHAR* argv[])
{
vector< int > vIntList;
for ( int i = 0; i < MAX_NUM; i ++ )
{
vIntList.push_back( i );
}
clock_t start, end;
double duration;
start = clock();
for ( vector< int >::iterator i = vIntList.begin(); i != vIntList.end(); i ++ )
{
( *i ) ++;
}
end = clock();
duration = ( double )( end - start ) / CLOCKS_PER_SEC;
cout << duration << "seconds" << endl;
start = clock();
for ( int i = 0; i < MAX_NUM; i ++ )
{
vIntList[i]++;
}
end = clock();
duration = ( double )( end - start ) / CLOCKS_PER_SEC;
cout << duration << "seconds" << endl;
return 0;
}
在Debug模式下执行的结果

Release模式下

可见,在Release版本中,它们几乎是一样快的。而在Debug版本中,可能因为迭代器需要额外的很多检查工作,所以比数组形式访问慢了很多很多……所以,对于采用哪种方式对vector进行遍历,效率怎样,如果最终是要发布为release版本的,那么这个问题大可不必担心。

Recent Comments